
FashionMNIST classification using LeNet-5 architecture
Hello? In this post we will look at how to implement the popular LeNet architecture using the Sequential module of PyTorch. We will be training on the Fashion MNIST, which was created to be a drop-in replacement for the MNIST. More details can be found in the Fashion MNIST paper here.
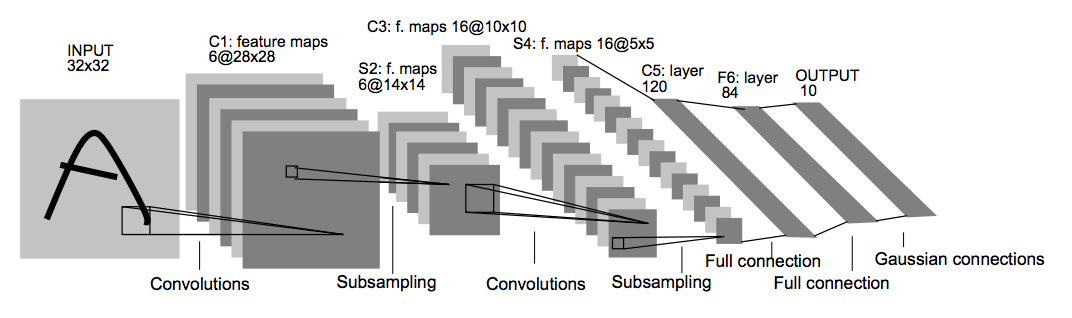
Overview of LeNet-5
LeNet-5 is a 7-layer convolutional neural network that was introduced in the paper of Yann LeCun, in which it was applied to document character recognition. At a high-level perspective, the LeNet-5 comprises of 3 parts namely; (i) two convolutional layers and (ii) a dense block consisting of three convolutional layers and sometimes uses sub-sampling or pooling layers between these layers. As for the training technique of this algorithm, each time an image is supplied to the network, the image is broken down into small slices known as local receptor fields. Since each neuron/unit in a layer is connected to neurons in the previous layer, the neurons can then extract visual elementary features from these local receptor fields such as edges and corners. These features are the combined in the latter layers of the network to in order to map/form higher-order features. The LeNet model was trained on the regular MNIST data set comprised of 60,000 images, of which 50,000 were used for training and 10,000 for testing using the mean squared error as the loss function for 20 iterations. The network achieved an error rate of 0.9%. In our task, we will be applying LeNet-5 to the Fashion MNIST data, but first, let’s import some dependencies!

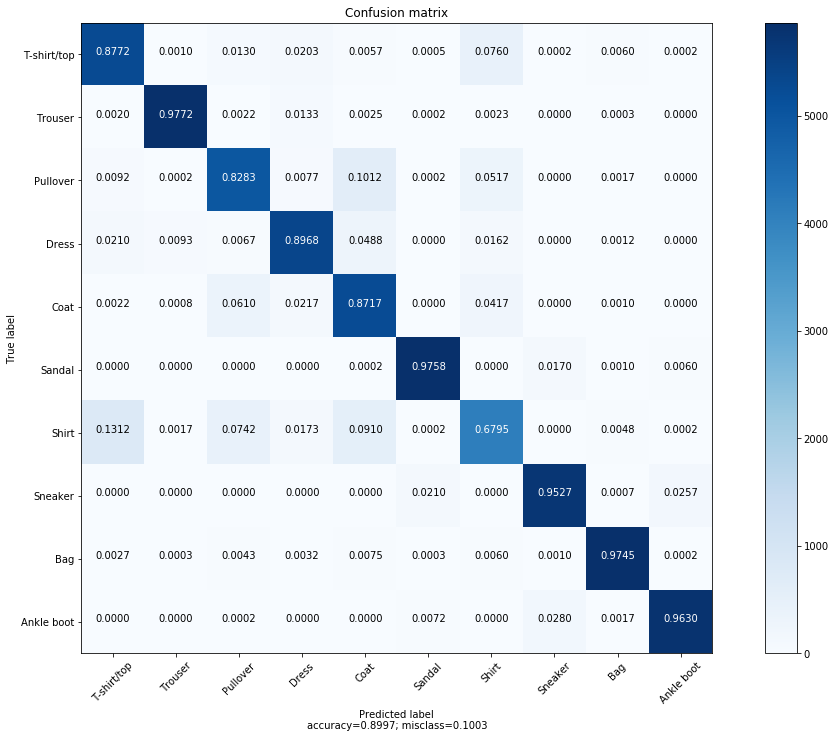
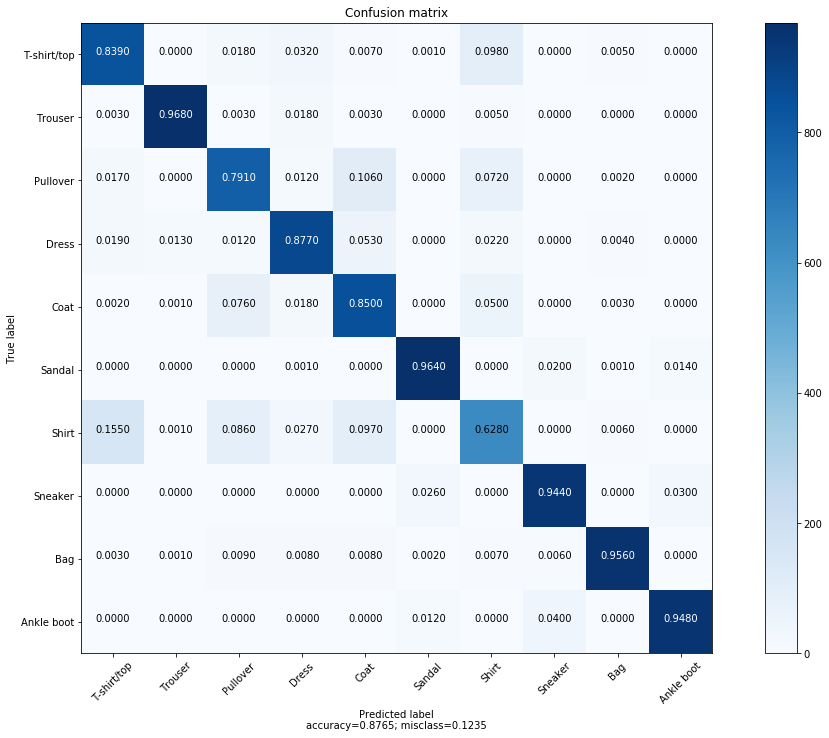
- Our LeNet-5 got a majority of the class labels correct. In the previous post using a custom CNN we got 90% train accuracy and 78% on the valid set. LeNet-5 got 0.89% train accuracy and 0.87% on the held-out test-set. This is a worthwhile performance boost from the initial results. However, there are a few things we might need to factor in at this point.
- The paper of Yifan Wang, here, discusses an improvement on MNIST based on a modified version of LeNet-5. In fact, at the time of the original LeNet-5, it hadn’t yet been discovered that the activation fucntion ReLU (rectified linear unit) is better than Sigmoid used in the original model. The Sigmoid is an S-shaped response function that returns 0 or 1 in the output. One setback of the Sigmoid is that it inhibits information flow during training (saturation), thereby leading to data loss. To fix this problem, ReLU avoids negative signals. If the input is negative, the ReLU returns an output of 0 otherwise it remains positive, in other words Max thresholding at 0. It was also discovered that ReLU is 6 times faster in convergence than the classic Sigmoid and reduces the chances of overfitting making the network more efficient. In their paper, Wang applied these changes and got an error rate of 0.7% on MNIST. However, our task involves the FashionMNIST, so we won’t get similar performnce as the Fashion MNSIT is more challenging than traditional MNIST digit data set.
- Now that we have learned about ReLU, let’s go ahead and re-design our LeNet-5, baring in mind these changes. We shall also use Adam to optimize the improved LeNet-5 and inspect the performance as before.
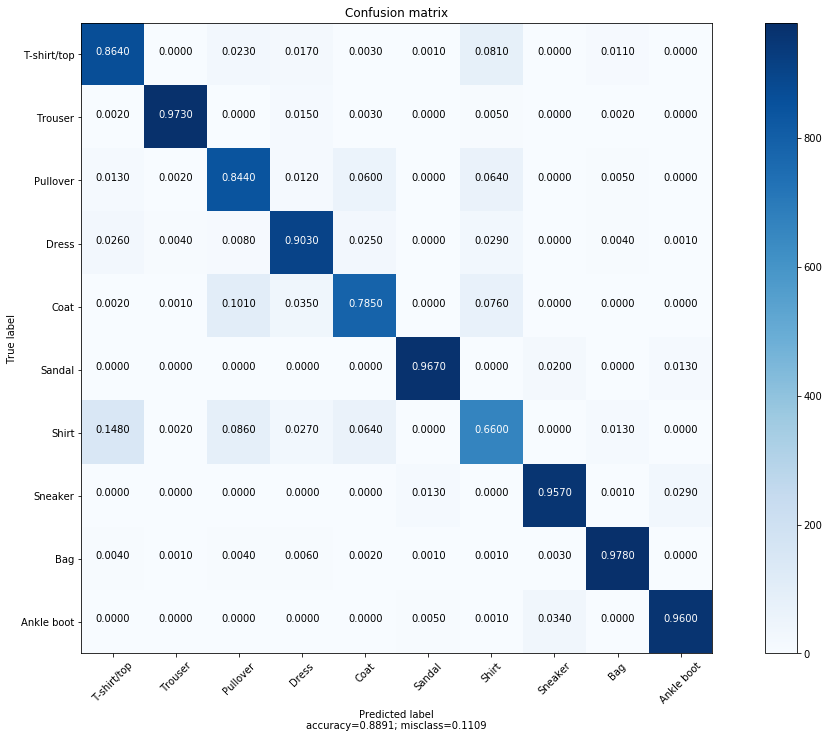
Conclusion
- We have demonstrated how to use the Sequential module to design a CNN.
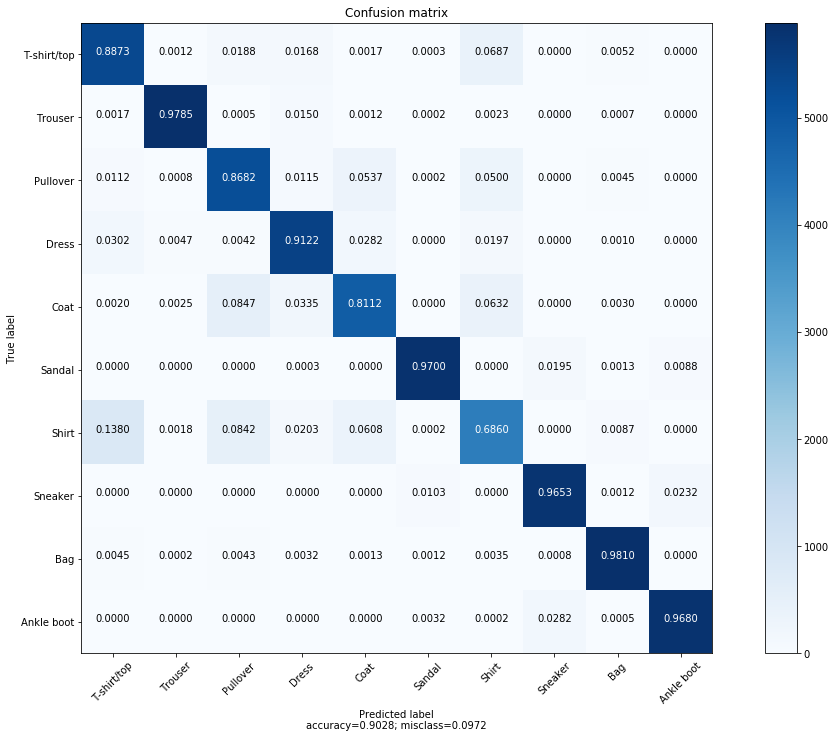
- LeNet-5 with ReLU activation offers a slight improvement over the original LeNet-5 with Sigmoid activations.
- Our ReLU’d LeNet-5 gave us approximately 90% for the training and almost 90% (88.9%) for the out-of-sample performance.
- We have also shown that our custom CNN from the previous post has been outperformed by the LeNet-5.
- It’s also worth noting at this point that, the class “Shirt”, was more harder of the CNN’s to classfify as shown in the confusion matrix. Also misclassification stands at about 9-11% which is better than the 21% of the custom architecture.
- Remember, we can train for more epochs to improve the accuracy of these CNN’s, however, we have to be careful not to overfit.